
티스토리 뷰
유용한 링크: MIT 강의 자료
어떤 문자열이 있고, 각 알파벳에 바이너리를 할당한다. 할당된 바이너리는 어떤 것이 다른 것의 prefix가 되면 안 된다. 문자열을 알파벳에 할당된 바이너리로 표현할 때 바이너리의 크기를 최소화하는 문제가 있다. 이는 매우 일반적인 압축 알고리즘을 필요로 하는 상황이다. Huffman Coding은 이 문제에 대한 최적해를 $O(N \lg N)$ 시간에 구한다. 각색은 다르지만, Huffman Coding과 같은 상황인 문제는 BOJ 13975번 파일 합치기 3이 있다.
Huffman coding - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Technique to compress data Huffman tree generated from the exact frequencies of the text "this is an example of a huffman tree". The frequencies and codes of each character are below.
en.wikipedia.org
Hu-Tucker algorithm은 위와 같은 상황이지만, 알파벳의 순서가 중요한 경우에 필요한 알고리즘이다. 즉, 사전순으로사전 순으로 앞에 오는 알파벳은 할당된 바이너리도 사전 순으로 앞에 오도록 하고 싶은 상황에 필요하다. Skew heap을 이용하여 구현하면, $O(N \lg N)$ 시간안에 구현할 수 있다. 마찬가지로 각색은 다르지만, Hu-Tucker algorithm이 필요한 문제로 BOJ 19089번 파일 합치기 4가 있다. 상황과 비슷한 각색의 문제로 AtCoder Typical Contest 002 C 최적 이분 탐색 트리 문제가 있다. 두 문제가 비슷한 입력 형식을 가지고 있다.
Hu-Tucker algorithm에서 Huffman Coding과 마찬가지로 두 빈도를 합쳐나가는 과정을 반복하지만, 두 수를 합칠 수 있는 조건이 다르다. Huffman Coding에서는 빈도 수가 가장 적은 두 값을 하나로 합쳤었다. Hu-Tucker algorithm에서는 두 수 사이에 기존 수가 하나도 없으면 하나로 합칠 수 있다고 한다. 합칠 수 있는 두 수가 있으면 두 수의 합이 가장 작은 것들부터 합친다. 이해를 돕기 위해 예시 상황을 보자.
다음과 같이 각 알파벳이 등장하는 횟수(빈도)가 있다고 하자.
[1, 2, 23, 4, 3, 3, 5, 19]
초기에는 인접한 두 수만 합칠 수 있다. 인접한 두 수 중 합이 제일 작은 쌍은 (1, 2)다. 둘을 합쳐 3을 넣자.
[3, 23, 4, 3, 3, 5, 19]
여기서 3은 볼드 처리가 안되어있는데, 이는 기존 수가 아닌 새로 추가된 수임을 의미한다.
다음으로 합이 제일 작은 합칠 수 있는 두 수는 (3, 3)이다. 둘을 합쳐 6을 넣자.
[3, 23, 4, 6, 5, 19]
이 때, 4와 5는 서로 합칠 수 있는데, 4와 5 사이에는 기존 수가 하나도 없기 때문이다. 합이 제일 작은 합칠 수 있는 두 수는 (4, 5)다. 둘을 합쳐 9를 넣자. 9가 들어갈 수 있는 위치는 기존 4와 5 사이 어디든 상관없다.
[3, 23, 9, 6, 19]
다음으로 합이 제일 작은 합칠 수 있는 두 수는 (9, 6)이다. 둘을 합쳐 15를 넣자.
[3, 23, 15, 19]
다음으로 합이 제일 작은 합칠 수 있는 두 수는 (3, 23)이다. 둘을 합쳐 26을 넣자.
[26, 15, 19]
다음으로 합이 제일 작은 합칠 수 있는 두 수는 (15, 19)이다. 둘을 합쳐 34를 넣자.
[26, 34]
마지막으로 합칠 수 있는 두 수는 (26, 34)이다. 둘을 합쳐 60을 넣자.
[60]
수가 하나만 남았으므로 알고리즘은 종료된다.
지금까지 합친 과정을 그림으로 나타내면 다음과 같다:

이 초기 결과에서 해결해야 할 문제가 하나 있다. 바로, 9와 6이 만들어지는 선분들이 서로 교차하고 있기 때문에 이 트리에서 올바른 인코딩을 구할 수 없다. 위 이진트리에서 각 리프 정점에 루트와의 거리(즉, 노드의 깊이이자 할당된 바이너리 길이)를 적어보면 다음과 같다.
[1(3), 2(3), 23(2), 4(4), 3(4), 3(4), 5(4), 19(2)]
이제 이진트리를 올바르게 만들어주기 위해 다음과 같은 과정을 진행한다.
제일 먼저 제일 깊은 깊이가 4인 정점 4개를 순서대로 이어준다.
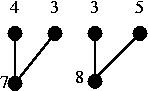
깊이가 4인 정점을 2쌍 이어주었기 때문에 깊이가 3인 정점이 2개 더 생겨서 4개 있는 것과 같다.
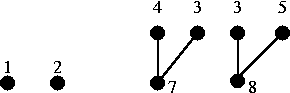
이제 깊이가 3인 정점 4개를 순서대로 이어준다.
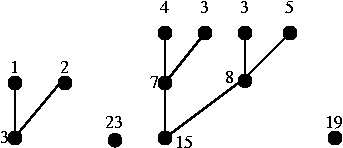
깊이가 2인 정점 4개를 순서대로 이어주고, 깊이가 1인 정점에 대해서도 처리하면 다음과 같은 결과가 나온다.

이 알고리즘이 올바르게 동작하기 위해서 다음 명제들을 증명해야 한다.
1. Hu-Tucker algorithm의 초기 결과에서 위와 같은 방법으로 올바른 트리를 항상 구할 수 있다.
2. Hu-Tucker algorithm의 초기 결과의 비용(각 알파벳의 빈도 수와 할당된 바이너리 길이를 곱한 값들의 합)이 최적해다.
1번 명제에 대한 증명은 MIT 강의 자료에 나와있고, 2번 명제에 대한 증명은 나와있지 않다. 아무래도 2번 명제에 대한 증명이 매우 까다로운 듯하다. 강의 자료에 따르면 초기 논문들에서 나온 증명은 틀렸다고 한다.
자, 그러면 마지막으로 남은 것은 이것을 구현하는 방법에 대한 것이다. 이 알고리즘은 증명도 까다롭고, 구현도 간단하지 않다. 다음 그림은 Hu-Tucker algorithm의 중간과정을 그림으로 표현한 것이다. 기존 수는 검은 동그라미, 기존 수가 아닌 것은 파란 동그라미로 그려졌다. 초록색 덩어리들을 하나로 묶어서 Skew heap(두 힙을 하나로 합치는데 $O(\lg n)$ 시간이 걸리는 힙)으로 구현이 비교적 간단하다.

초록 직사각형이 하나의 Skew heap을 나타내고, heap 안에는 초록색 직사각형 안에 있는 파란 동그라미에 적힌 빈도수가 들어있다. 자세한 구현은 아래 첨부된 코드를 참고하자. 첨부된 코드는 위에서 소개한 BOJ 19089번 파일 합치기 4 문제를 푸는 코드다. 시간복잡도는 $O(N \lg N)$이다.
여담) Skew heap을 쓰지 않고, 일반적인 heap을 이용하여 구현도 가능하다. 임의의 두 heap $A$와 $B$를 합치는 과정을 알아보자. 일반성을 잃지 않고 $|A| \geq |B|$라고 하자. 이때, $B$의 원소들을 하나씩 pop 하면서, $A$에 push 해주면 전체 시간복잡도가 $O(N \lg^2 N)$으로 늘어나지만 실제 실행 시간이 Skew heap을 사용했을 때보다 조금 더 빨랐다.
'공부' 카테고리의 다른 글
| 선형점화식 빠르게 계산하기 (2) | 2022.11.30 |
|---|---|
| 다항식 나눗셈의 몫을 빠르게 구하는 방법 (3) | 2022.11.29 |
| Skew Heap (0) | 2022.05.03 |
| Z-function (2) | 2021.03.08 |
| Li Chao Tree (Dynamic Convex Hull Optimization) (0) | 2021.03.08 |
- Total
- Today
- Yesterday
- BOI
- Tree
- BOI 2009
- Parametric Search
- optimization
- Dijkstra
- Segment tree
- idea
- IOI2014
- Boyer-Moore Majority Vote Algorithm
- vote
- Boyer
- TRIE
- Algorithm
- HackerRank
- IOI2013
- IOI2011
- moore
- majority
- Divide & Conquer
- USACO
- Splay Tree
- Greedy Method
- ioi
- Knuth Optimization
- Dynamic Pramming
- BOI 2001
- dynamic programming
- z-trening
- IOI2012
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |